A sketch of string unescaping on GPGPU
In a modern computer, the GPU has vastly more raw computing capability than the CPU. Some tasks (like text painting, which I redid recently in xi-mac in OpenGL) lend themselves well to efficient computation in the GPU, because they’re naturally parallel. Other tasks seem innately serial. It’s the ones in the middle where I think things will get interesting.
The task I’ve been pondering lately is JSON parsing. While it’s most natural to think of it in sequential terms, I believe it is possible to formulate it in terms of parallel computation. This post will focus on a specific fragment, string unescaping. It is an important to the overall problem, but more to the point it captures the seemingly sequential nature of parsing. In particular, an extra quote or backslash near the beginning of the input can affect a parse decision taken much later. Even so, I will demonstrate that the problem can be solved in parallel, with significant speedup over the scalar CPU case, though I don’t believe it’s quite practical yet.
There’s some precedent for my exploration, including nvParse, a GPU-based parser for CSV, and a fair amount of work in SIMD parsing, of which Mison and pikkr are two of the most promising and interesting.
State machine
As with most simple parsing techniques, I’ll start with a state machine, shown in the following diagram:
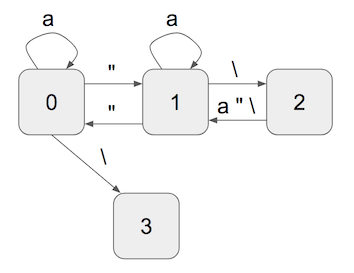
The initial state is 0. A quote mark moves to state 1, which means “in a string.” In a string, a backslash moves to state 2, which means “after backslash.” Any character in state 2 moves back to state 1, and a quote in state 1 is interpreted as a closing quote, which moves back to state 0, ready for the next string. In addition, a backslash appearing outside a string (ie in state 0) is an error, and I reserve state 3 for that.
I’ll define (a very simplified version of) the string unescaping problem as retaining all characters in state 1 and discarding the rest. There’s more to real JSON unescaping, like resolving \n into newline, decoding 4 hex digit Unicode escapes, and (particularly ugly), handling “astral plane” Unicode by decoding two adjacent \u sequences representing the UTF-16 encoding of the codepoint. However, all these other details can be computed using only a small local window on the input, so are not “hard.”
Encoding this state machine into sequential code is nearly trivial, and my code for it is about 15 lines (optimized for clarity rather than speed or conciseness).
State machine as monoid homomorphism
The usual evaluation of a state machine is as a purely sequential process. Start with an initial state, then, sequentially for each input symbol, transition to the next state based on the previous state and the symbol.
However, it’s possible to express it as an associative function, (a monoid homomorphism, to be more precise), an idea well articulated in the post Fast incremental regular expression matching with monoids. That’s worth reading, but I’ll try to recap it here, using the specific state machine shown above.
Basically, map each symbol to a function from state to state. Since there are only 4 states, there are 256 such functions, strongly suggesting the use of a byte to represent them. In this case, all the functions we care about map 3 to 3 (the error state), so there are only 64 such functions. It’ll be convenient to represent them as 3-tuples, one final state for each initial state (if the initial state is 3, then the final state is also always 3).
A quote mark is (1, 0, 1), and a backslash is (3, 2, 1). A regular character (neither quote nor backslash, depicted as “a” in the diagram above) is (0, 1, 1).
To make it into a monoid, we need two more things: identity, and an associative operator. Identity (corresponding to the empty string) is simple: it’s (0, 1, 2). The associative operator is just a little trickier. Using Python-like notation, if our inputs are a and b, then the composition is (b[a[0]], b[a[1]], b[a[2]]). I’ll give a couple of examples: aa evaluates to (0, 1, 1), same as just a. But \a maps to (3, 1, 1). Outside a string, it maps to the error state. Starting from state 1, the backslash moves to state 2, then the a back to state 1. And starting from state 2, the backslash is interepreted as an escaped character, moving us to state 1, then the a stays in state 1.
This composition operator is associative (as is function composition in general) but is not commutative. For example, a\ is (3, 2, 2).
Prefix sum
After mapping the input symbols into these functions, the state of the state machine after each symbol can easily be recovered from the prefix sum of the functions, computed over the function composition operator, a generalization from the usual addition operator. There’s quite a bit of good literature on efficient parallel computation of prefix sums. I’ll refer the interested reader to the Wikipedia description, as it’s quite good and has pretty pictures. The short answer is that you gather up larger and larger blocks, using lg(n) parallel steps, then distribute those back down to individual leaves in lg(n) more steps. In a clever work-efficient variant, the total number of operations is only 2n.
Prefix sum over a monoid homomorphism is a good, general technique. For example, in xi-editor, it’s used to convert between offset and line number in O(log n) time in a rope data structure. There, the focus is incremental computation, but it’s also useful for extracting parallelism.
Implementation in CUDA
Prefix sum is an important enough operation that many libraries to ease parallel programming directly support it. To prototype my idea, I used Thrust, which is now bundled with CUDA. I could have written a prefix scan myself, but using Thrust saved me a lot of time.
The details of my code are reasonably straightforward. I use a byte representation of the state-to-state function, a 4-tuple with each entry encoded as 2 bits. The mapping from input byte to function is map_fsm, and the function composition operator is compose_fsm. The latter uses some bit magic to unpack and repack the 2-bit values into the tuple, but is recognizably the same as the Pythonish fragment above.
The Thrust transform_inclusive_scan function combines the map from symbol to function, and the prefix scan over functions, into one operation.
Stream compaction
The prefix sum computes the state after each symbol, but the statement of the problem also includes discarding all input characters other than those in state 1. The general problem is known as stream compaction, and again Thrust directly supports it, using the copy_if family of functions.
It may not immediately be obvious how this can be computed in parallel. One way to formulate it is as a prefix sum over 0 for discarded entries, 1 for retained ones, resulting in a destination index for each retained entry. Then, a scatter operation writes each retained entry. The scatter operation is somewhat expensive (in particular, it consumes global memory bandwidth, a scarce resource), but increasingly it is directly supported by GPU hardware.
Experimental results
The GPU version runs at about 4GB/s on my laptop (Gigabyte Aero 14 with GPX 1060). The scalar version is about 200MB/s. That’s encouraging, but I don’t think it’s quite compelling evidence that the idea is practical. For one, the CPU version could definitely be improved, using SIMD and just general coding techniques.
Even so, it is evidence that this simple parsing problem can be expressed in parallel in a way that’s computable on a GPU. I believe (without having done serious performance analysis) that the bottleneck is the use of global memory bandwidth. A more sophisticated approach would separate the input into tiles, do as much processing as possible on each tile using faster shared, rather than global, memory, then reassemble the tiles at the end. However, I find myself daunted by the prospect of actually programming that; it feels like it would require a massive time investment to understand the finer-grained details of GPGPU performance.
If nothing else, I hope I’ve presented an interesting thought experiment, about how it how it might be possible to implement sequential-seeming problems in parallel anyway.