Swapchains and frame pacing
This is something of a followup to the compositor is evil, but more of a guide on how to optimize latency, and less of a rant. I’m starting to collect performance measurements of piet-gpu running on Android, and ran into unexpectedly poor frame rates, which re-opened this topic. Simply increasing the number of images in the swapchain fixed the throughput problem, but I was also worried about the impact on latency. Exploring that led me down a deep rabbit-hole.
My primary interest is improving the performance of (2D) UI graphics, but the modern graphics stack is strongly driven by the needs of 3D graphics, especially games. Graphics performance is a tradeoff between throughput, latency, and power, with smoothness sometimes also a consideration (for movie playback it makes sense to use a deeper buffer to minimize the chance of a dropped frame). Different applications tend to use different strategies for swapchain presentation, but in this post I will propose something of a unified strategy, suitable for both UI and 3D intensive applications.
Front and back buffers
Let’s wind the clock back about 25 years, to a video game console or PC in the Nintendo 64 class (or even 30 years ago, to an SGI Indigo, which had similar graphics but was much more expensive and less widely available).
At that time, it was traditional for UI to be drawn using a single display buffer. The application would draw its graphics by writing into that buffer, and concurrently the video would be scanned out by reading from that memory. Sometimes that led to flickering artifacts, but generally not too bad, as an application would generally write the final pixels for a region fairly quickly, rather than leaving it in an intermediate partly-drawn state for long enough for the scan to catch it.
But such an approach would be completely unworkable for 3D. There, you start with a completely blank buffer, then draw in one triangle at a time, using Z testing so if the newly drawn triangle is farther away than the one in the buffer, the pixel is discarded. After all triangles are drawn, the scene is complete. But if you were to scan out during this process, you’d see a terrible flickery half-drawn mess.
The standard solution is double buffering. One buffer is designated the “front buffer,” and video scanout occurs from that. The other buffer is the “back buffer,” and it is free for the application to scribble on. Once painting is complete, the app swaps the two buffers, the front buffer becoming back and vice versa, so scanout occurs from the current front buffer.
There are two choices regarding syncronization with the frame rate. With “vsync off,” scanout immediately switches to the newly rendered frame, and the formerly front buffer immediately becomes available for rendering the next one. This is ideal for both throughput and latency, but the downside is a “tearing” artifact, as the frame presented to the user contains horizontal bands of different rendered frames.
With “vsync on,” the actual swap is deferred until the end of scanout of the current frame, so scanout of the next frame begins at the top. At the same time, the formerly-front, newly-back buffer is not available for writing until that vsync moment, so any operations that would write onto the frame must block for the frame to become available. In a well-written app, the time between the frame being presented and the next vsync where the other buffer is available can be used for other things, for example processing inputs or running game systems such as physics simulation, as long as those things don’t write the buffer. In OpenGL, this is arranged by a synchronization point. The swap itself (for example, glXSwapBuffers) returns immediately, but the next call to OpenGL that requires write access blocks.
A typical game loop looks like this then:
while true:
process inputs
do simulation etc
glClear()
draw the game
glXSwapBuffers()
In systems of this era, generally the 3D acceleration functions as a co-processor to the main CPU, basically synchronously executing commands (or with a small queue), so the latency between the CPU initiating a drawing command and it completing with a write to buffer memory is short. Good models include the Nintendo 64 and Playstation 2. (Note though that even in these early days, there was signficant architectural diversity, and the Dreamcast employed tile-based deferred rendering, which lives on today in many mobile GPUs).
Overall, it looks like this:

Faster hardware → latency regression
Running on the hardware for which this game was designed, performance is good. It takes about 16ms to render the frame, but that’s all useful work. There’s little slop in the system, and that small amount of slop serves a useful function: it gives a little safety margin to decrease the risk of a frame drop.
But consider this situation. Say the next generation of hardware runs exactly twice as fast, and you run the same game on it. You’d expect performance to improve, right?
Wrong. In fact, latency has actually regressed by 8ms. Let’s look at a timeline to see what’s gone wrong.

The amount of time needed to render a frame has improved by 8ms, so in theory a latency gain of 8ms should also be possible. But this timeline shows that there are two sources of slop, each about 8ms. The first is the blocking glClear() call, and the second is the fully rendered frame sitting in the back buffer waiting for the next vsync.
As graphics systems become more complex, there are even more opportunities for this kind of latency regression. However, even this simple case shows that there is need for some kind of frame pacing.
Triple buffering
One approach to this problem is triple buffering. Instead of a single back buffer, there are two; one ready for display, and the other being drawn. The “swap” call now swaps between these two without blocking. At vsync, the display engine grabs the buffer that’s ready and swaps it with the front buffer.
In the limit as GPU performance approaches infinitely fast, this approach gives “as good as possible” latency without tearing. However, there are at least two problems.
The most obvious is the wasted power consumption for rendering frames which will then be entirely discarded. Even ignoring the carbon footprint, keeping the GPU busy like this can result in thermal throttling, which reduces performance in other ways.
A more subtle issue is that smoothness isn’t as good as it might be; the delay between the start of the game loop and the scanout jitters by a uniform distribution of zero to one GPU rendering interval. When the GPU is very fast, that might not be noticeable, but when the FPS is just under the refresh rate of the monitor, triple buffering can add a significant amount of jitter (compared to double-buffered vsync on) with little improvement in latency.
While triple buffering is at least moderately popular for games, I know of no UI toolkit that employs triple buffering with an unconstrained frame rate, and the power concerns basically take it off the table for mobile. Thus, I am not recommending it, and will suggest other techniques for attaining the same goal.
Asynchronous rendering
One of the big changes since the Nintendo 64 era is that the interaction between CPU and GPU has become much more asynchronous, and modern APIs such as Vulkan, Metal, and DX12 expose that asynchrony to the application (OpenGL largely tries to hide it, with mixed success). Essentially, GPU work is recorded into command buffers, which are then placed into a queue, and completion of that unit of work happens some time later.
At the same time, the number of cores on the CPU has gone up. Let’s say that physics simulation takes about one frame time on a CPU, and recording the command buffers also takes about one frame time. Then, a very reasonable architecture is pipelining, where one thread does the physics simulation, hands it to another thread for rendering, then those recorded command lists are submitted to the GPU for another frametime, and finally scanout happens (or perhaps is delayed another frame due to the compositor, and a “game overlay” can easily add another frame of latency). Thus, we’re in a fun situation where modern hardware is something like 100 times faster than the Nintendo 64, but latency is maybe 50ms worse.
It is possible to mitigate the latency issues, but it takes serious engineering effort. Aside from frame pacing issues (the major focus of this blog), scalable multicore algorithms for things like physics simulation work better than pipelining, and it’s similarly possible to split up the work of recording into command buffers into multiple parallel threads — this is one of the biggest potential gains of Vulkan and other modern APIs over OpenGL.
An example of a game which has been seriously optimized for latency is Call of Duty, about which more later. A highly optimized game might look something like this:

Blocking synchronization in Vulkan
While the GPU of the Playstation 2 era is more or less synchronous, a modern GPU is very much asynchronous, and the resulting pipelining can improve performance a lot. Modern graphics APIs such as Vulkan give the programmer explicit control over the this asynchrony, with an emphasis on explicit synchronization primitives. Of course, that also extends to interactions with the swapchain.
The classic game loop in Vulkan looks like this:
while true:
process inputs; run game systems
vkAcquireNextImageKHR(swapchain, acquire_semaphore)
render game by building command buffers
vkQueueSubmit(cmdbufs, acquire_semaphore, present_semaphore)
vkQueuePresentKHR(present_semaphore)
Let’s break this down, as there’s a fair amount going on.
The acquireNextImage call requests a writable image from the swapchain. It may block for some time, but generally returns somewhat in advance of the image actually becoming available; if you were to immediately write to the image, that would be invalid. That is the purpose of the acquire semaphore — acquireNextImage promises to signal the semaphore when the frame is actually available.
That’s why the queue submit call takes an acquire semaphore. The call schedules the work onto the queue, but it may or may not begin running immediately. One reason it may be delayed is that the semaphore hasn’t been signaled yet, indicating that the swapchain image is not yet available for writing. (Other reasons it might be delayed include other GPU work in the queue that hasn’t completed yet)
The presentation call is similar. It’s a request to present the rendered image, but at the time the application makes the call, rendering may not have completed (indeed, it might not even have started).
This strategy basically tries to keep queues as full as possible. That’s great for throughput, but not necessarily ideal for latency. In addition, the actual behavior might be pretty different from one GPU to another. In my experimentation, I’ve seen both acquireNextImage and queuePresent block, depending on details of swapchain settings and workload.
Enter the compositor
The above discussion assumes fullscreen mode, ie scanout directly from the swapchain to the display. Modern systems generally add a compositor to the mix, so that the output from the application can be composited with other windows (and notifications and so on), and scanout happens from the compositor’s target surface (not visible to applications at all).
In theory, adding the compositor doesn’t change things much, other than adding one frame time of latency (more or less unavoidably, though on Linux there’s recent work to improve it) and taking the “vsync off” option off the table. Because of those limitations, it’s also common to offer a “fullscreen” option specialized for gaming that bypasses the compositor, often with special affordances for compositing notifications (the FLIP_DISCARD mode in DXGI is designed for this, see the note on “reverse composition” in this doc recommending flip modes).
The major complication is the presence of hardware overlays, which are a factor on both Windows and Android (and possibly other systems). The idea of a hardware overlay is that sometimes the contents of a window can be scanned out by the video hardware directly from an app-owned swapchain, rather than that swapchain simply being used as the texture source by the compositor (most of the time resulting in bit-identical RGB pixels in the compositor’s target buffer). The display adapter usually has a very small number of overlays available (3 or 4 is common), so it’s generally only available for the frontmost window. The compositor makes the decision heuristically, and the app is generally not involved.
On Windows, from my understanding, a hardware overlay window has one frame less latency. That’s generally good, but not necessarily good for smoothness, as transitioning between the overlay and fallback compositing can cause jank (and very likely audio synchronization issues for video playback). The details are not clear to me, and don’t seem to be well documented. If timing is critical to your Windows application, I recommend spending a lot of quality time in PresentMon in conditions where direct flip may be enabled and disabled.
Android takes a different approach. A hardware overlay window is scheduled for scanout at the same time as if it were composited using OpenGL, in other words the choice is effectively invisible to the user; the main benefit is reduced power consumption. However, one consequence is that the compositor may need to hold on to the swapchain buffer longer than would be the case in a fullscreen or Windows/mac style compositor, as it might be read until the end of actual scanout. Thus, the minimum acceptable value for the swapchain size (minImageCount in Vulkan-speak) to sustain a smooth framerate is 3 for Android, while 2 is fine on desktop.
However, if we use blocking-based synchronization and a swapchain size of 3, latency is quite bad. Basically, blocking-based synchronization tries to keep pipelines as full as possible, and the blocking calls cause input to grow stale while they block. To understand this better, it might be good to look at an actual systrace captured by Android GPU Inspector (from the current version of my code, actually):
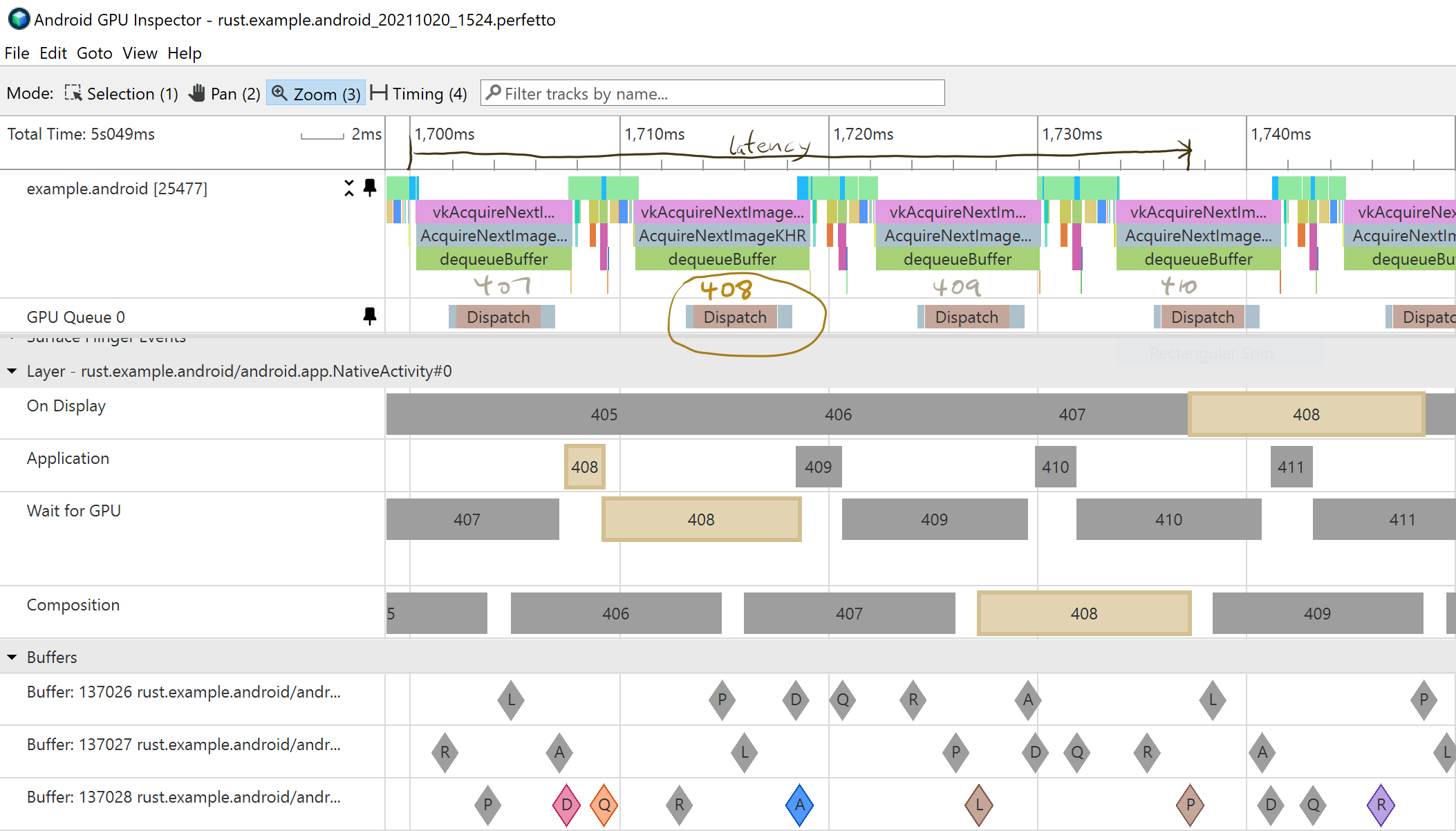
Here, frame 408 begins in the “game loop” around 1700ms — the input has been processed, and the app calls acquireNextImage. That blocks for 7ms until the system dequeues the buffer (the “D” diamond in the third buffer trace). However, the buffer is not actually available, it’s still in use for scanout of frame 405 to the display. Even so, ANI returns control back to the app at 1707ms, which then does about 2ms of CPU-side work to fill a command buffer, and calls vkQueueSubmit at about 1709ms, followed by vkQueuePresentKHR a few hundred µs later (“Q” for queue). The command buffer submission is controlled by a semaphore shared with the ANI call; basically ANI can return any time it likes, and promises to signal the semaphore when the buffer is actually available for writing, ie when it’s released from its use for scanout of frame 405. That happens at 1713ms (the “R” diamond), and triggers GPU work starting at 1713ms and lasting 5ms. Completion of that command buffer of GPU work signals the semaphore shared with the QP call, which lets SurfaceFlinger acquire the buffer at 1718ms (the “A” diamond). The next vsync for composition is at 1727ms, at which point SurfaceFlinger latches (“L”) the buffer. The buffer is eligible for hardware composition, so is held until scanout of frame 408 begins, at 1737ms (“P” for present).
How might we have done better? The actual deadline for the GPU to finish its rendering work is the “L” at 1727ms. That work is about 2ms of CPU and 5ms of GPU. Thus, if we had processed input and started rendering at 1720ms, we would have just barely made the deadline. And latency (from input to start of scanout) would have been reduced from about 37ms to about 17ms.
Another way of looking at this is the three intervals of blocking, in each of which the input grows increasingly stale: the blocking call to ANI (7ms), the wait from command buffer submission to the GPU actually starting work (4ms), and the time between rendering being complete and the deadline for it to be accepted by the compositor (9ms). The first two can and should go to 0 (it’s just waiting for a buffer to be available), but some safety margin should be retained in the third; if it gets too close to 0, the risk of dropping a frame goes up.
Frame pacing
Basically, relying on blocking calls for scheduling rendering is the old way, and gives particularly bad results on Android. The new way is to implement some form of “frame pacing.”
From first principles, you have a deadline for presenting a certain frame, and also an estimated probability distribution for how long the rendering will take. To optimize for input lag, that should take into account input processing as well, not just the drawing. The optimum time for starting the work is the deadline minus the (say) 99.99 percentile of that distribution (this would result in a jank event every minute or so).
Figuring out the deadline should be pretty straightforward; on a display with fixed refresh rate, it should just be multiples of the refresh interval. Things can get more complicated with variable refresh rate, but that’s largely out of the scope of this post (ideally, a good implementation of variable refresh lets the app miss the frame deadline by a small amount with only minimal consequences, as opposed to janking an entire frame).
The challenge, of course, is accurately estimating that distribution. A major component to that is observing past behavior, but that’s not all there is to it, either: input processing might be highly variable (especially depending on the inputs), and rendering time might be as well. Games tend to have fairly smoothly varying scene complexity, but that’s a design choice, and may be much less true for UI-centric applications.
To implement the strategy of scheduling the rendering work at just the right time so that it completes with a small amount of slop before the presentation deadline, there are two reasonable tactics.
The easiest is to estimate ahead of time the rendering interval, as an integral number of frame periods, and schedule rendering to begin at a vsync that number of frames before the present deadline. That is exactly the Microsoft recommendation — use a latency waitable object to signal a thread to begin rendering (rather than blocking in the Present call), and use SetMaximumFrameLatency to set the expected rendering time. A value of 2 might make sense for most games, but 1 might be better if the entire loop of simulation + rendering can be accomplished in a single frame, and 3 is also a plausible value if there’s more concern about frame drops than latency, or if the game systems and rendering are highly pipelined.
A more sophisticated approach is to use some kind of control loop to estimate the rendering time, and schedule it adaptively, with timing granularity that can be a fraction of a frame time. Such a control loop needs to know a fair amount of information about what’s actually happening in presentation, including the frame rate (which might be variable, especially on mobile where it might be throttled for power reasons) and statistics for how close past rendered frames came to missing the deadline (or, of course, when they did miss the deadline). This information is not considered part of standard graphics APIs such as Vulkan, but is available on specific platforms.
In particular, on Android there is the VK_GOOGLE_display_timing extension. This has a call to get the display rate (for predicting future deadlines), and another to query the past presentation timings, in particular by exactly how much the presentation beat the deadline. Further, it extends queuePresent so that you can request presentation in the future, not necessarily the next vsync. That’s especially important when rendering at a slower pace than the display’s refresh (increasingly important as high-refresh displays become common).
If you’re writing an Android game, it might be easier to just use the frame pacing library (also known as Swappy), which wraps these lower-level calls in a convenient interface. It may make assumptions more suited to games, but is also battle-tested and should work well.
There is work towards evolving this Android-specific extension into a Khronos standard, driven in large part by Wayland. See this Phoronix article on present timing for more details. There’s also lots of detailed discussion in the VK_EXT_present_timing proposal thread itself. Keith Packard has been working on display timing in Linux and blogging about it; that blog post also contains a link to 2019 talk which well motivates the problem and explains some of the challenges of solving it.
It is also possible to get past presentation statistics on Windows, using GetFrameStatistics, and games that have been optimized for latency use it to control the scheduling of rendering work. An excellent case study is Controller to display latency in Call of Duty, which goes into great detail (and covers some of the same ground as this blog).
Also note that Windows 11 is a major upgrade on this front, with a composition swapchain API that provides most of the features needed for good frame pacing, including insight into whether there’s a hardware overlay, ability to request presentation of a frame at a specific timestamp, and ability to revise frames in the queue even after they’ve been placed there. I haven’t experimented with it yet, but one question I have is whether it supports smooth resize, or whether that’s still broken by design. The documentation is not reassuring on this front, as it doesn’t explicitly discuss window resize.
There is evidence that a lot of Windows games are suboptimal when it comes to frame pacing. One such indication is the the existence of SpecialK, an open-source tool that dynamically tweaks games (their SwapChain science page goes into some of the same issues as this post), in many cases showing dramatic improvement.
Animation timebase
The major focus of this blog post is minimizing latency, specifically by precision timing of the start of rendering of each frame. There’s a related problem, also known under the “frame pacing” umbrella, which is providing an accurate timebase for running the animations and physics simulations. In the case where presentation is running at a consistent 60Hz, this is not a hard problem, but to deal with variation, it gets trickier. Just sampling the CPU clock is not accurate and may in some cases produce visible stuttering even if the presentation of frames is consistent. The talk Myths and Misconceptions of Frame Pacing goes into some detail on that.
One important observation from that talk is that a consistent 30Hz appears smoother than any hybrid where some frames are displayed for 16.6ms and others for 33.3. A major feature of Swappy is determining when the frame rate should be downgraded, then reliably scheduling frames for presentation — unlike the full frame rate case, it’s possible for a frame to arrive too early. As high refresh rates become more common, especially on phones (the recently released Pixel 6 Pro has 120Hz), getting this right is important.
Some control theory
Predicting the total rendering time is a really hard problem, for a variety of reasons. For one, it can depend on completely external factors, such as load from other processes running on the same system.
But a special reason it’s hard is that rendering time may depend on when frames are scheduled, which in turn depends on the output of the predictor. A particularly likely manifestation of that feedback loop is clock frequency control on the GPU. That’s usually its own controller, applying its own heuristics based on the workload. It’s not possible in general for the app to even query the clock frequency, though of course there is device-specific access, to support profiling tools.
For example, an app might decide to downgrade FPS based on some lost frames (let’s say due to transient workload, such as an assistant running some machine learning workloads on the GPU). The GPU driver will happily scale down its frequency, which is good for battery, but that also gives feedback to the controller that the GPU performance has degraded, so it should sustain the low frame rate. Restarting the game would restore the higher frame rate, but there’s no way for the controller to know that, so it stays stuck at the low rate. I’m not sure if there’s any good solution to these kinds of system-wide performance factors, but I think it’s worth looking into.
Measure, measure, measure
Performance engineering depends critically on accurate measurement of the performance targets. In this case, that’s input-to-photon latency. It’s easy to get misled by looking only at software traces; the only way to really get to the source of truth is measurement on a real, physical system. Tristan Hume has an excellent blog post on a keyboard to photon latency tester, which touches on display timing issues as well.
Another invaluable source of information is system traces (ideally validated by measuring photons as above). On Android, systrace (or Perfetto for the UI version) is the tool of choice, and is conveniently available as part of Android GPU Inspector. On Windows, use Event Tracing for Windows, and also PresentMon for analyzing data specific to display presentation. On mac, the Instruments application gives nice timing data.
Conclusion
Frame pacing is a poorly understood and oft overlooked aspect of the total performance story, especially as it affects latency. Doing things the simplest way will generally optimize for throughput at the expense of latency.
On Android in particular, the default strategy (2 frame swapchain, blocking present calls) will produce especially poor results, not even keeping up with the maximum frame rate. Fortunately, the Swappy library provides a good solution to frame pacing. On other platforms, you need to dig deeper. While most of the attention has been on games, applying these kinds of techniques should also significantly improve UI latency.
On systems other than Android, the frame pacing story is still evolving. Standardization of techniques for reliably measuring and controlling display timing will help a lot. In addition, faster display refresh rates will also improve latency. We may look forward to a future in which we can expect games and other graphical applications to have latency better than the Nintendo 64, rather than worse.
After posting this article, I learned of a similar blog post on Fixing Time.deltaTime in Unity, detailing fairly recent improvements in frame pacing in that engine.
Thanks to Ian Elliott for explaining some of the arcane details of how Android manages swapchains.
Discuss on Hacker News.