Fast 2D rendering on GPU
Previously on my quest for fast rendering of 2D vector graphics on GPU, I have posted a piet-gpu update and a deeper exploration into a sort-middle architecture. These intermediate results showed promise, but fell short of my vision for truly high performance 2D GPU rendering.
I am now pleased to present an architecture that I believe does realize this vision. The performance is impressive, but more than that, the architecture is derived from principles and is founded on a general pipeline, as opposed to being a collection of hacks in the service of benchmark results. As much work as possible is offloaded to the GPU, which minimizes the risk of jank in UI rendering and lets us exploit the continuing performance improvements in GPU technology.
Further, this rendering pipeline is well suited both for fully dynamic and (partially) static content. It does not rely on precomputation, instead quickly processing the scenes into tiles for “fine rasterization” at the end of the pipeline. Even so, static fragments of the scene can readily be retained and stitched together, so that the CPU-side cost is minimized.
In short, I firmly believe that this is the architecture to beat.
I also want to be up-front about the limitations of the work. First, the imaging model is still fairly limited, as I’ve been focusing on path rendering. I believe that the general nature of the pipeline makes the architecture amenable to a richer imaging model such as SVG or PDF, but until that’s actually implemented, it’s somewhat speculative. Second, the implementation relies heavily on GPU compute capabilities, so will not run on older hardware or drivers. I should also note that Pathfinder has a much better story on both fronts; in particular it has a “mix and match” architecture so that much work besides the fine rasterization can be done on CPU.
Another limitation is that complex scenes can require lots of memory. Certainly the current implementation doesn’t do anything clever to deal with this, it just allocates buffers which are hopefully big enough. There are ways to deal with it, but unfortunately it is a source of additional complexity.
The code is now merged to the main branch of the piet-gpu repo.
How it works
I’m not going to go into extreme detail here, rather try to provide an overview.
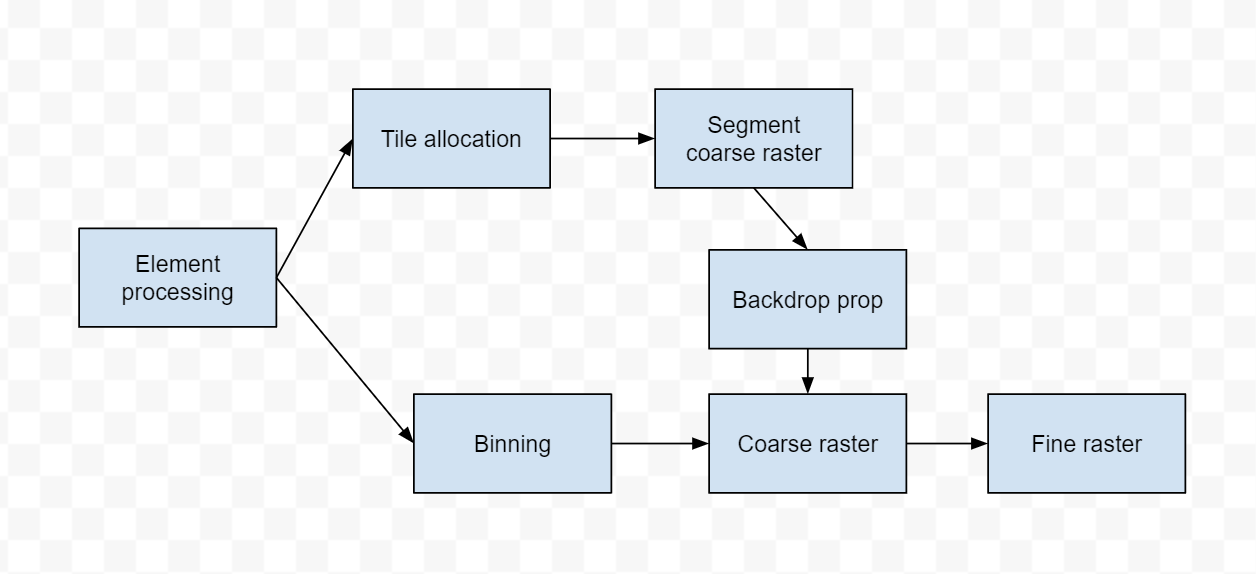
The architecture is firmly based on the previous sort-middle design. The major difference, though, is the handling of path segments. In the previous design, all elements, path segments included, were carried through the pipeline in sorted order to fine rasterization. Empirical evaluation showed that plumbing elements through the pipeline had a nontrivial cost.
Given this evidence, the solution became clear. Individual path segments within a path do not need to be kept sorted at all. For a fill, the total winding number (or exact area calculation in the case of antialiased rendering) is the sum of the contributions from each path segment. Similarly, for distance field rendering of strokes, the final distance is the minimum of that to each stroke segment. In both cases, the operation is associative and commutative, so the individual elements can be processed in any order.
Thus, the pipeline splits into two parts; a sort-middle path for filled and stroked paths (and, in the future, other graphic elements), and an unsorted pipeline for path segments. To coordinate the two, each path is assigned an id (just a sequence number, really), and each path segment is ascribed to its corresponding path’s id. A simple tile allocation kernel allocates and initializes a rectangular region of tiles for each path. Then coarse path rasterization proceeds directly from the path segments, drawing into the tile structures by using an atomicExchange to insert segments into a linked list structure.
Coarse rasterization in the sorted pipeline is similar to the previous sort-middle architecture, with some refinement. It inspects the rectangular tile region for each path, and marks non-empty tiles using an internal bitmap (this is a highly parallel and load-balanced operation). Then, each thread processes one tile, and outputs commands for each element that was so marked, in sorted order.
Backdrop processing is actually more straightforward than the previous version. When backdrop is needed (a path segment crossing a horizontal tile boundary), there’s just a simple atomicAdd of +1 or -1 to the backdrop for that tile. Then, another kernel performs a prefix sum across a scanline of tiles, propagating that backdrop to the right. Tiles with nonzero backdrop but also no path segments get a “solid color” command. One of the nice things about this architecture is that there is no O(n^2) for highly complex paths, as there was in previous iterations.
To me, the performance is satisfying in a way not fulfilled by previous iterations, not only because it’s fast (it is), but because it’s understandable. Every cost in the pipeline has a reason. You have to keep paths sorted and composite them in order, and there’s a cost to doing that. But only paths, not segments within a path, so the cost is a lot less. And a nice feature of the pipeline is “performance smoothness;” there aren’t workloads where the performance degrades.
GPU-side flattening
There are two major lines of approach in the 2D rendering literature. One is for curves to interact directly with pixels. The other is for curves to be flattened into polylines first. Both approaches have advantages and disadvantages. Basically, lines are simpler to handle, but there are more of them.
Previously, following Pathfinder, I had the flattening on the CPU. The current codebase is the first iteration that moves the flattening to GPU. It uses the fancy new flattening algorithm, though there is nothing particularly fancy about the implementation; though the algorithm has features that are helpful to parallel implementation, such as computing the exact number of subdivisions before producing any of the points, this was a fairly straightforward implementation, each thread processing one curve.
An earlier version of the code, before GPU flattening, had a highly parallel, load balanced implementation of “fat line rendering” of lines, but I didn’t retain this for the curve-flattening version. It should be possible to combine the two; the general approach would be a queue of line segments stored in shared memory, with curve flattening filling the queue and another stage draining it, doing the output to global memory. This remains as future work, especially as performance is pretty good as-is. The algorithm is clever, and I hope I get a chance to describe it in more detail.
Doing flattening on the GPU unlocks layer optimizations, even in the presence of zoom and rotation. Almost certainly, the most important practical consequence is font rendering — a glyph can be rendered at any size, actually with arbitrary affine transformation, without any re-encoding work on the CPU.
Performance discussion
First, a disclaimer. Performance evaluation of GPU renderers is hard. There are so many variables, including details of drivers, effects of presentation and the compositor, pipelining because there are async stages, which sources of overhead to count and which can be amortized over multiple frames. Because GPUs are so fast, even a small CPU cost for uploading data is significant. Also, quality of support for timer queries varies a lot (though it’s pretty good for Vulkan). Because of all that, the performance numbers should be taken with a grain of salt. Even so, I think the measurements are good enough to demonstrate the massive improvements we see over rendering techniques that involve the CPU.
These measurements were done on a Gigabyte Aero 14 laptop with an Intel i7-7700HQ CPU, and both an Nvidia GTX 1060 and integrated HD 630 graphics, running Windows 10. The output canvas is 2048x1536 for piet-gpu and generally similar for the other renderers. The scale factor is 8x for tiger and 1.5x for paper-1 and paris-30k.
I compare three renderers. For piet-gpu I am counting only the rendering time, not encoding. I feel this is fair because it is designed to reuse encoded layers; they can be rotated, zoomed, and subjected to arbitrary affine transformations. The cost of encoding is on the same order of magnitude as rendering; for tiger it is about 200us, and about an order of magnitude less than parsing the SVG. Any application will need a way to retain layers some way or other in order to achieve good performance.
For Pathfinder I am comparing only the master branch (at 0f35009). I take the maximum of CPU and GPU times, assuming that they are pipelined. This is generous, as the assumption might not be valid, for example if the CPU is highly loaded doing other processing for the application. I should also note that there is a development branch which moves most of the tiling to the GPU and is showing extremely promising performance, comparable to piet-gpu.
For Cairo I am benchmarking using the --perf option to resvg’s rendersvg tool. I am counting only the “rendering” and not “preprocessing” times. The latter would add about another 50% to the total time. I also tried the raqote backend and found it to be approximately 1.5x to 2x slower than Cairo.
I should also note that, unlike last time around, I am applying correct stroke style to the paris-30k example, by doing preprocessing beforehand. This adds somewhat to rendering time, and makes the comparison with other renderers more fair. I am hopeful that it is possible to apply stroke styles GPU-side, through a combination of distance field rendering techniques (especially good for round joins and caps) and path-to-path transformations, which would probably have a performance profile broadly similar to flattening.
And now the graphs:
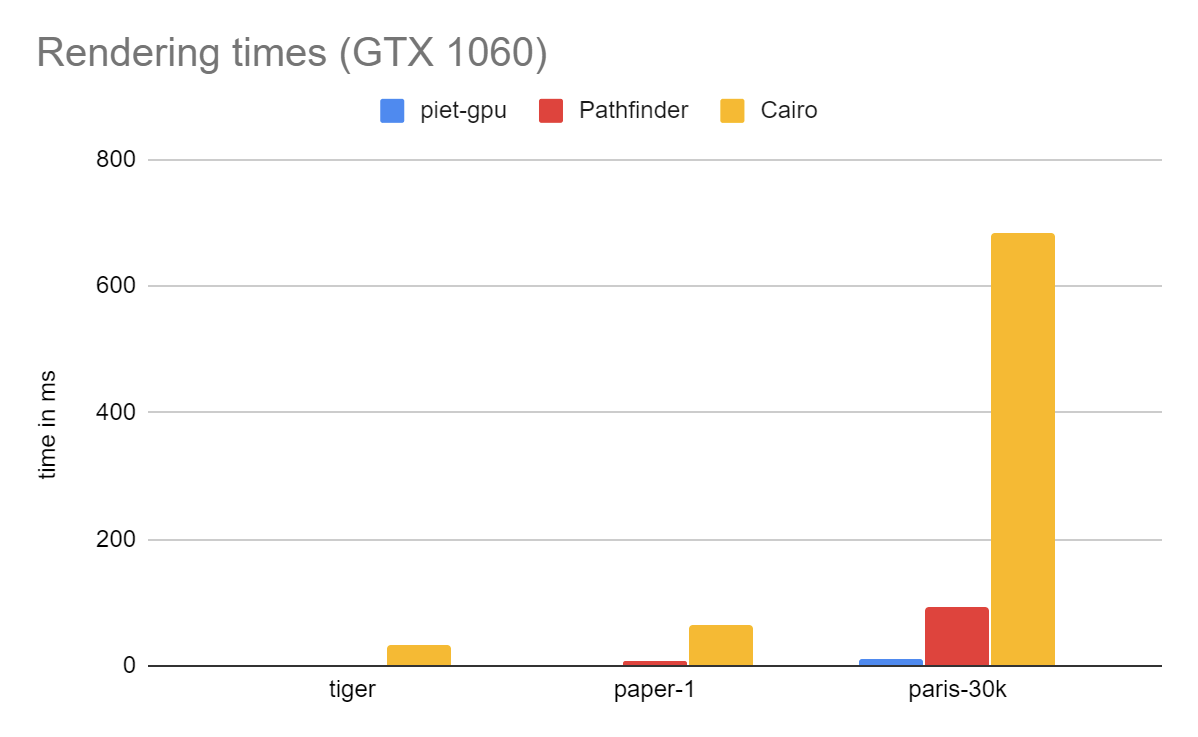
Since the amount of time taken by piet-gpu rendering is barely visible, let’s rescale the y axis to a maximum of 50ms:
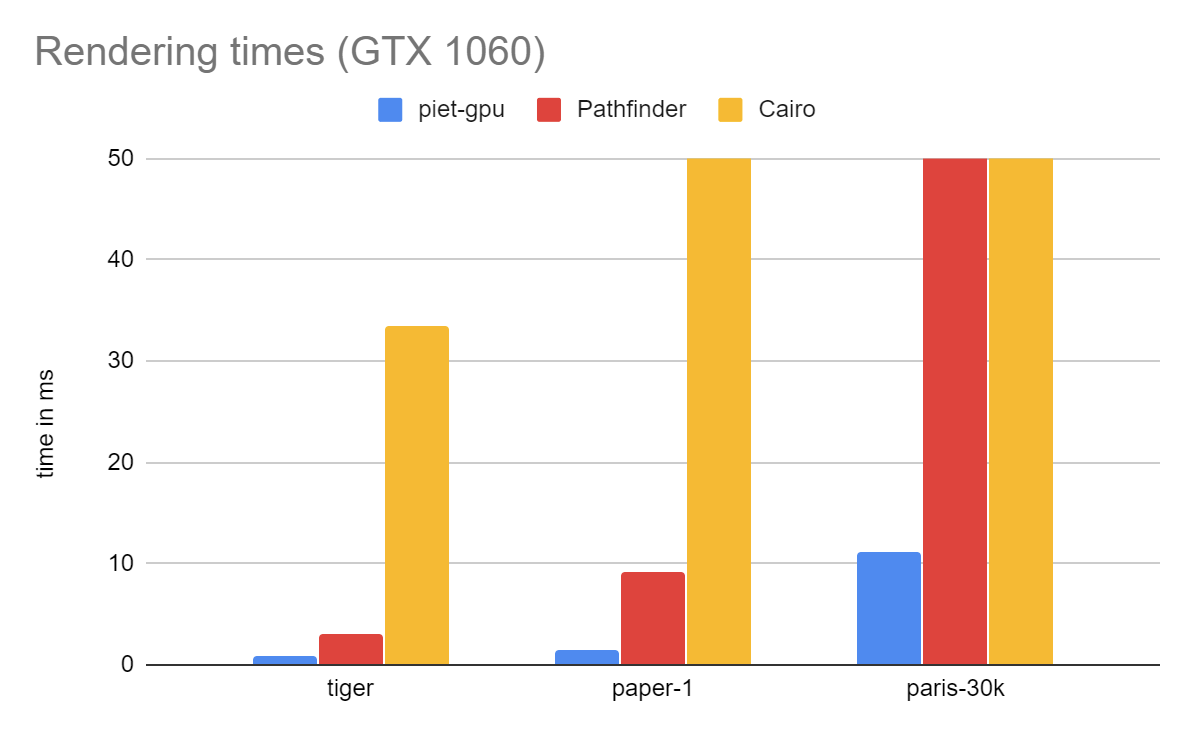
I find these really exciting results. Moving rendering to GPU means that interactive frame rates are possible even with very complex documents, and even on Intel 630 the paper-1 example (dense vector text) runs in 7.6ms, meaning 60fps is possible with plenty of room to spare. (More detailed measurements are in a spreadsheet, but as a general rule of thumb, the Intel HD 630 is about 5x slower than the GTX 1060). I am unaware of any published renderer with comparable performance, though I believe Li et al comes close, and it is entirely possible that Spinel is faster; it is just very difficult to evaluate.
Unfortunately, a lot of software we use today is stuck on CPU rendering, which has performance nowhere near what is possible on GPU. We should do better.
Comparison with previous post
I’m not going to go into a lot of detail comparing the current codebase with the previous post. I saw the fraction of time going into coarse rasterization go down, but then as I made changes to add GPU-side flattening, the time went up. Of course, the overall performance is dramatically better because it is now capable of transformable vector layers, and previously that would have required re-flattening on the CPU. In addition, I am aware of a number of opportunities for optimization, so I am quite confident I could bring the numbers still lower. But this obsessive optimization takes a huge amount of time and effort, and at some point I question how valuable it is; I believe the current codebase stands in proving the ideas viable.
Discussion and prospects
I believe I have demonstrated convincingly that moving almost all of the 2D rendering task to the GPU is viable and yields excellent performance. Further, the ideas are general, and should adapt well to a range of graphics primitives and fine rendering techniques. I believe it would hold up well as an academic paper, and would like to find the time to write it up as such.
Having got this far, I’m not sure how much farther I want to take the piet-gpu codebase. I think an ideal outcome would be to have the ideas folded into existing open-source renderers like Pathfinder, and am encouraged by progress on that front. Even so, I believe there is some benefit to exploring a GPU-centric approach to layers.
All of this work has been on my own time. In accordance with my licensing policies, everything is published under a permissive open source license, and with no patent protection, unlike other libraries such as Slug. Going forward, my time is pretty well spoken for, as I’m going to be working on Runebender and druid full-time with generous financial support from Google Fonts. But I encourage people writing new 2D rendering engines to consider the techniques I’ve explored, and might be open to consulting arrangements.
People who are interested in more details (as this post is something of a high level overview) may want to read the design document I wrote after implementing the previous sort-middle architecture and before starting coding on this. And there’s a ton of quite detailed discussion on the #gpu stream on the xi zulip (signup required, open to anyone with a Github account).
I’ve learned a lot from this, and hope others do too. And I hope we can collectively get to a world where jank in GUI and other 2D rendering applications is unusual, rather than the norm. The hardware can certainly support it, it’s just a question of building the engine and integrating it into applications.
Many thanks to Patrick Walton for stimulating discussions which have helped clarify design questions.